📌 목차
0. 분석 요약
1. 핵심 지표 선정
2. 가설 검증 - 가설 1
3. 가설 검증 - 가설 2
4. 가설 채택
5. 문제 정의
이전 글 | 사이드 프로젝트 : 배달 데이터 분석(2) - 현황 파악, 문제 정의를 위한 가설 설정
이전 분석 요약
1. 프로젝트의 목적 : 주문율 개선
배달 서비스의 핵심 성과 지표는 '주문율'이다.
2. 현황 파악 : 전환율, 이탈률
주문 수 및 주문율 분석
- 전체 사용자 중 76.92%가 한 번도 주문하지 않았고, 주문 경험이 있는 사용자는 약 23%에 불과했다.
- 단순 주문율 = 40.98% (결제 클릭 수 / 홈 화면 노출 수)
퍼널 분석
주요 단계
- 방문 단계: 홈 화면 방문 (screen_view)
- 탐색 단계: 음식 검색, 배너 클릭 등 (click_search, click_restaurant 등)
- 장바구니 단계: 메뉴 장바구니 추가 (click_cart)
- 결제 시도 단계: 결제 버튼 클릭 (click_payment)
전환율
잠재 고객군의 전환율이 가장 낮으며, 고객의 충성도가 높아질수록 전환율이 개선되는 경향을 확인

| 전환 단계 | 평균 전환율 |
| 방문 → 탐색 | 34.83% |
| 탐색 → 장바구니 | 14.62% |
| 장바구니 → 결제 시도 | 60.51% |
| 장바구니 → 결제 시도 (주문 0회 포함) | 45.38% |
세그먼트별 단계별 전환율
[방문 → 탐색] 단계
- 잠재 고객: 28.11% 전환
- 저관여 고객: 33.21% 전환
- 고관여 고객: 38.21% 전환
- 충성 고객: 39.77% 전환
[탐색 → 장바구니] 단계
- 잠재 고객: 3.76% 전환
- 저관여 고객: 11.62% 전환
- 고관여 고객: 14.51% 전환
- 충성 고객: 28.57% 전환
[장바구니 → 결제 시도] 단계
- 잠재 고객: 0% 전환
- 저관여 고객: 58.98% 전환
- 고관여 고객: 62.54% 전환
- 충성 고객: 60.00% 전환
이탈률
잠재 고객군의 이탈률이 가장 높으며, 고객의 충성도가 높아질수록 이탈률이 개선되는 경향을 확인
| 이탈 단계 | 평균 이탈률 |
| 방문 → 탐색 | 65.18% |
| 탐색 → 장바구니 | 85.38% |
| 장바구니 → 결제 시도 | 39.49% |
| 장바구니 → 결제 시도 (주문 0회 포함) | 54.62% |
세그먼트별 단계별 이탈률
[방문 → 탐색] 단계
- 잠재 고객: 71.89% 이탈
- 저관여 고객: 66.79% 이탈
- 고관여 고객: 61.79% 이탈
- 충성 고객: 60.23% 이탈
[탐색 → 장바구니] 단계
- 잠재 고객: 96.24% 이탈
- 저관여 고객: 88.38% 이탈
- 고관여 고객: 85.49% 이탈
- 충성 고객: 71.43% 이탈
[장바구니 → 결제] 단계
- 잠재 고객: 100% 이탈
- 저관여 고객: 41.02% 이탈
- 고관여 고객: 37.46% 이탈
- 충성 고객: 40% 이탈
3. 분석 결과
- 방문한 사용자 중 상당수가 탐색 단계에서 이탈하며, 탐색 경험 개선이 필요하다.
- 장바구니까지 이동한 사용자는 비교적 높은 확률로 결제까지 진행하므로, 탐색 → 장바구니로 이어지는 과정의 전환율을 높이는 것이 중요하다.
- 주문 경험이 없는 사용자 그룹에서 높은 이탈이 발생하며, 이들이 주문으로 이어지도록 유도할 전략이 필요하다.
4. 가설 설정
분석 결과를 바탕으로 주문율 향상을 위한 가설을 설정하였다.
각 가설이 실제 데이터로 검증 가능한지를 판단하기 위해, 가설에 필요한 핵심 지표들을 선별하고 해당 지표가 데이터에 존재하는지 평가하였고, 이를 통해 검증할 수 있는 가설과 데이터 부족으로 인해 검증이 어려운 가설을 구분하였다.
가설 검증 진행 가능 여부 판단 결과
| 가설 | 내용 | 가능 여부 |
| 가설 ❶ | 담고 싶은 메뉴가 없어서 이탈했을 가능성이 크다. | O : 검증 가능 |
| 가설 ❷ | 재방문 횟수가 많을수록 주문율이 높아질 것이다. | O : 검증 가능 |
| 가설 ❸ | 탐색 과정에서 불편함을 겪어 이탈했을 것이다. | X : 데이터 부족 |
| 가설 ❹ | 가격이나 배달비 부담으로 주문을 포기했을 것이다. | X : 데이터 부족 |
| 가설 ❺ | 리뷰·식당 정보 부족으로 신뢰도가 낮아져 주문을 포기했을 것이다. | X : 데이터 부족 |
.
요약
이전 분석에서는 배달 서비스의 주문율을 높이기 위해 현황을 파악하고 문제를 정의를 위한 가설 설정 과정을 다루었으며,
이번 분석에서는 데이터 분석 결과 기반의 가설 검증을 수행하여, 명확한 문제 정의 과정을 작성하였다.
1. 가설 검증을 위한 핵심 지표 설정
가설 검증을 위해 핵심 지표를 선정하고, 데이터 분석 결과에 기반하여 가설을 검증한다.
1.1 핵심 지표 선정
가설을 검증하기 위한 핵심 지표 선정
가설 ❶ 담고 싶은 메뉴가 없어서 이탈했을 가능성이 크다.
[핵심 지표]
- 탐색 후 장바구니 전환율 : 탐색 → 장바구니 (메뉴를 발견한 후 장바구니에 추가하는 비율)
- 탐색 <> 장바구니 일치율 : 클릭한 음식 vs 장바구니에 담은 음식 비교
가설 ❷ 재방문 횟수가 많을수록 주문율이 높아질 것이다.
[핵심 지표]
- 재방문 수 및 재방문율: 세그먼트 별 재방문 횟수 및 재방문율 비교
- 주문율 (장바구니 → 결제 시도 전환율): 세그먼트 별 주문을 진행한 비율
2. 가설 검증 : 담고 싶은 메뉴가 없어서 이탈했을 가능성이 크다
2.1 탐색 → 장바구니 단계 전환율 검정
2.1.1 분석 목적 및 방법
- 목적: 각 고객 세그먼트별로 사용자가 탐색 후 실제 장바구니에 담은 비율(전환율)의 차이가 있는지 확인
- 방법: 카이제곱 검정을 통해 각 세그먼트의 전환된 고객 수와 전환되지 않은 고객 수를 비교하여, 세그먼트 간 전환율 차이가 통계적으로 유의한지 평가
2.1.2 데이터 요약 및 검정 결과
탐색 후 장바구니 전환율
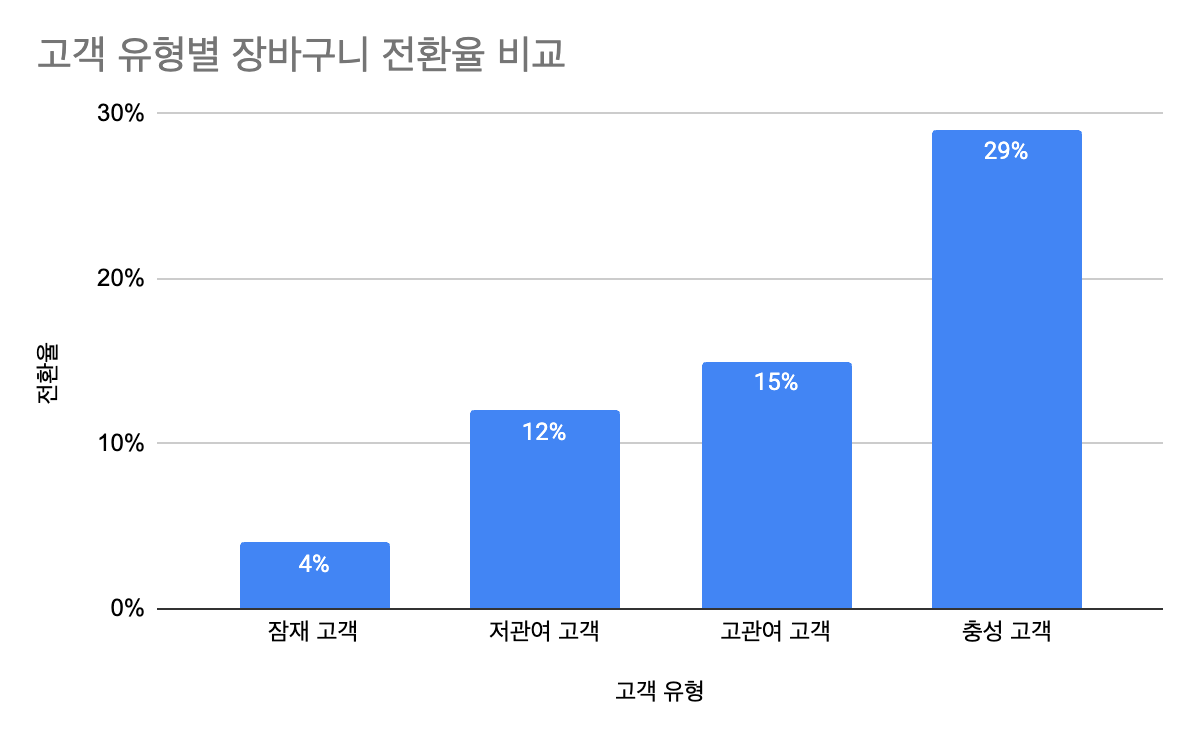
| 고객 유형 | 전환된 고객 수 | 전환되지 않은 고객 수 | 전환율 |
| 잠재 고객 | 1,115 | 28,278 | 4% |
| 저관여 고객 | 958 | 7,284 | 12% |
| 고관여 고객 | 299 | 1,761 | 15% |
| 충성 고객 | 10 | 25 | 29% |
from scipy.stats import chi2_contingency
import numpy as np
# 전환율 데이터: [전환된 고객 수, 전환되지 않은 고객 수]
conversion_data = np.array([
[1115, 28278], # 잠재 고객 (4%)
[958, 7284], # 저관여 고객 (12%)
[299, 1761], # 고관여 고객 (15%)
[10, 25] # 충성 고객 (29%)
])
chi2, p, dof, expected = chi2_contingency(conversion_data)
print(f"카이제곱 통계량: {chi2:.4f}")
print(f"p-value: {p:.4f}")
검정 결과:
- 카이제곱 통계량: 1012.9916
- p-value: 0.0000
- 세그먼트 간 전환율 차이가 통계적으로 유의미함 : 귀무가설 기각
➡️ 유의수준 0.05 기준에서 p-value가 매우 낮으므로, 세그먼트 간 장바구니 일치율 차이가 통계적으로 유의미함을 확인
2.2 장바구니 일치율 검정
2.2.1 분석 목적 및 방법
- 목적 : 고객 세그먼트(주문 횟수별) 간에 탐색 후 장바구니에 담긴 음식의 일치율 차이가 있는지를 확인
- 분석 방법 : 카이제곱 검정을 사용하여 각 세그먼트별(잠재 고객, 저관여 고객, 고관여 고객, 충성 고객)의 장바구니 일치율(클릭한 푸드 ID 대비 실제 장바구니에 담긴 비율) 차이가 통계적으로 유의미한지 평가
데이터 요약 (세그먼트별 장바구니 일치율):
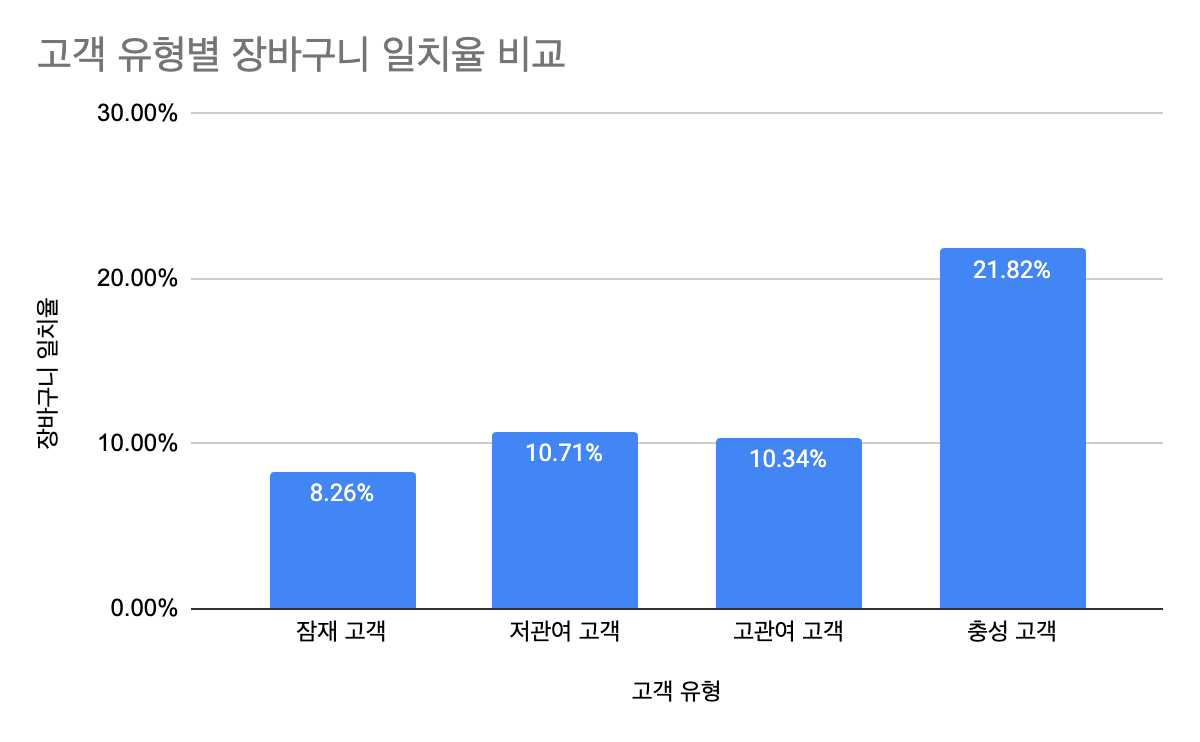
| 고객 유형 | 장바구니 일치율 | 일치한 클릭 수 | 불일치한 클릭 수 | 전체 클릭 수 |
| 잠재 고객 | 8.26% | 1,537 | 17,067 | 18,604 |
| 저관여 고객 | 10.71% | 1,053 | 8,779 | 9,832 |
| 고관여 고객 | 10.34% | 298 | 2,585 | 2,883 |
| 충성 고객 | 21.82% | 12 | 43 | 55 |
# 세그먼트별 장바구니 일치율 데이터: [일치한 클릭 수, 불일치한 클릭 수]
cart_match_data = np.array([
[1537, 17067], # 잠재 고객 (8.26%)
[1053, 8779], # 저관여 고객 (10.71%)
[298, 2585], # 고관여 고객 (10.34%)
[12, 43] # 충성 고객 (21.82%)
])
chi2_cart, p_cart, _, _ = chi2_contingency(cart_match_data)
print(f"\n장바구니 일치율 검정 - 카이제곱 통계량: {chi2_cart:.4f}")
print(f"p-value: {p_cart:.4f}")
검정 결과
- 카이제곱 통계량: 61.0539
- p-value: 0.0000
세그먼트 간 장바구니 일치율 차이가 통계적으로 유의미함 : 귀무가설 기각
➡️ 유의수준 0.05 기준에서 p-value가 매우 낮으므로, 세그먼트 간 장바구니 일치율 차이가 통계적으로 유의미함을 확인
2.3 상관관계 분석
2.3.1 장바구니 일치율과 주문 횟수 상관분석
- 목적 : 장바구니 일치율과 주문 횟수 간의 관련성 확인
- 분석 방법 :
- Pearson 상관분석: 연속형 변수 간의 선형 관계 강도를 확인
- Spearman 상관분석: 데이터의 수가 적거나, 정규분포를 가정하기 어려운 경우에도 관계의 방향과 강도를 확인하기 위한 추가 수행
상관분석 결과
| 분석 항목 | 분석 기법 | 상관계수 | p-value | 해석 |
| 장바구니 일치율 vs 주문 횟수 | Pearson | 0.8705 | 0.1295 | 강한 양의 상관관계 있으나, 표본 수 제한로 통계적 유의성 미흡 |
| 장바구니 일치율 vs 주문 횟수 | Spearman | 0.8000 | 0.2000 | 강한 양의 상관관계 있으나, 표본 수 제한로 통계적 유의성 미흡 |
➡️ 집단(세그먼트) 수준에서는 4개의 데이터 포인트(각 세그먼트 대표값)로 상관분석을 수행하였으므로, 자유도가 매우 낮아 p-value가 유의수준을 충족하지 못하는 한계가 있음
2.3.2 결론
전환율 검증 결과
고객 세그먼트 간 탐색 후 장바구니 전환율의 차이는 p-value 0.0000으로 매우 유의미하게 나타남
→ 주문 횟수가 증가할수록 사용자가 원하는 메뉴를 발견하여 장바구니 전환율이 상승함을 의미
장바구니 일치율 검증 결과
세그먼트 간 장바구니 일치율 역시 p-value 0.0000으로 유의미한 차이를 보임
→ 집단 수준에서 주문 횟수와의 상관분석 결과는 강한 양의 경향을 나타내지만, p-value가 유의수준 0.05를 충족하지 않아 통계적 유의성이 확보되지 않았음
2.4 최종 결론
가설 ❶ ("담고 싶은 메뉴가 없어서 이탈했을 가능성이 크다") : 가설 기각
- 장바구니 전환율과 일치율에서 세그먼트 간 차이가 통계적으로 유의미하게 나타났지만, 주문 횟수와 일치율의 상관분석에서 통계적 유의성을 확보하지 못해, 가설을 채택하기엔 부족함
- 보다 명확한 인과관계를 위해 추가 데이터 수집 및 분석이 필요함
3. 가설 검증 : 재방문율이 높을수록 주문율이 높아질 것이다
3.1 재방문율 집단 간 차이 검정
각 세그먼트의 재방문율에 유의미한 차이가 있는지 검정
3.1.1 분석 목적 및 방법
- 목적: 각 고객 세그먼트별로 고객의 재방문율에 유의미한 차이가 있는지 확인하고, 재방문율이 높아질수록 주문율 증가에 기여하는지를 검증하기 위함
- 방법: 고객 세그먼트별 재방문율의 분포 차이를 비모수 검정인 Kruskal-Wallis 검정을 수행하여 통계적 유의성을 평가
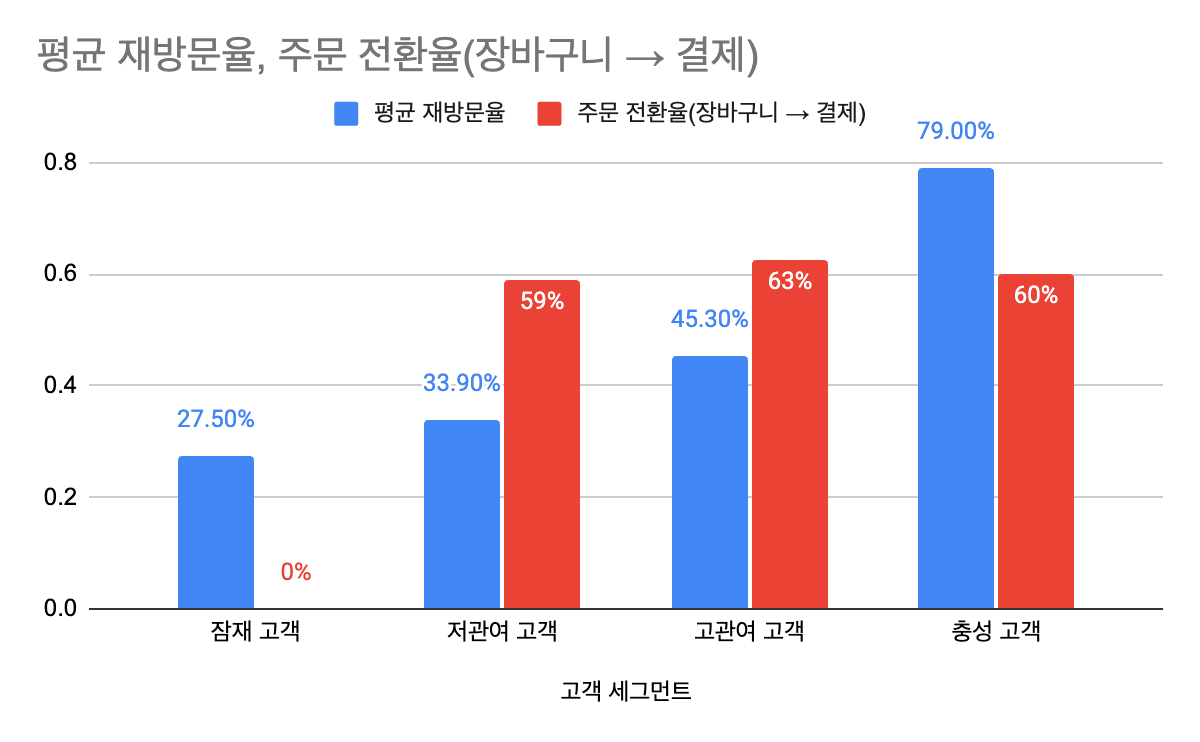
데이터 요약 (세그먼트별 평균 재방문율) :
| 고객 세그먼트 | 평균 재방문율 |
| 잠재 고객 (주문 0회) | 약 27.5% |
| 저관여 고객 (주문 1회) | 약 33.9% |
| 고관여 고객 (주문 2~3회) | 약 45.3% |
| 충성 고객 (주문 4회) | 약 79.0% |
*계산 방법: 각 세그먼트에서 NaN이 아닌 재방문율 값들의 합을 해당 값의 개수로 나누어 평균 산출
세그먼트별 재방문율 데이터
*각 값는 해당 코호트(FirstVisit)별로 특정 기간(코호트 기간 1, 2, …)의 재방문율을 나타냄, 0열은 기준으로 항상 1.0으로 설정
잠재 고객 (주문 0회)
| FirstVisit | 0 | 1 | 2 | 3 | 4 | 5 |
| 2022-08-01 | 1.0 | 0.1753 | 0.3132 | 0.3193 | 0.3330 | 0.2038 |
| 2022-09-01 | 1.0 | 0.3213 | 0.3147 | 0.3282 | 0.2033 | NaN |
| 2022-10-01 | 1.0 | 0.3258 | 0.3307 | 0.2138 | NaN | NaN |
| 2022-11-01 | 1.0 | 0.3317 | 0.2045 | NaN | NaN | NaN |
| 2022-12-01 | 1.0 | 0.2061 | NaN | NaN | NaN | NaN |
| 2023-01-01 | 1.0 | NaN | NaN | NaN | NaN | NaN |
저관여 고객 (주문 1회)
| FirstVisit | 0 | 1 | 2 | 3 | 4 | 5 |
| 2022-08-01 | 1.0 | 0.2133 | 0.3829 | 0.3829 | 0.3864 | 0.2349 |
| 2022-09-01 | 1.0 | 0.4003 | 0.3442 | 0.3826 | 0.2485 | NaN |
| 2022-10-01 | 1.0 | 0.3865 | 0.4019 | 0.2574 | NaN | NaN |
| 2022-11-01 | 1.0 | 0.4513 | 0.2860 | NaN | NaN | NaN |
| 2022-12-01 | 1.0 | 0.3220 | NaN | NaN | NaN | NaN |
| 2023-01-01 | 1.0 | NaN | NaN | NaN | NaN | NaN |
고관여 고객 (주문 2~3회)
| FirstVisit | 0 | 1 | 2 | 3 | 4 | 5 |
| 2022-08-01 | 1.0 | 0.3241 | 0.4793 | 0.5172 | 0.5241 | 0.3310 |
| 2022-09-01 | 1.0 | 0.5372 | 0.4855 | 0.5475 | 0.3326 | NaN |
| 2022-10-01 | 1.0 | 0.5507 | 0.6190 | 0.4058 | NaN | NaN |
| 2022-11-01 | 1.0 | 0.6287 | 0.4371 | NaN | NaN | NaN |
| 2022-12-01 | 1.0 | 0.6094 | NaN | NaN | NaN | NaN |
| 2023-01-01 | 1.0 | NaN | NaN | NaN | NaN | NaN |
충성 고객 (주문 4회)
| FirstVisit | 0 | 1 | 2 | 3 | 4 |
| 2022-08-01 | 1.0 | 0.6000 | 0.8000 | 0.8000 | 0.6000 |
| 2022-09-01 | 1.0 | 0.7778 | 0.5556 | 0.7778 | 0.7778 |
| 2022-10-01 | 1.0 | 1.0000 | 1.0000 | 1.0000 | NaN |
검정 결과
- 검정 통계량: 11.5871
- p-value: 0.0089
세그먼트 간 재방문율 차이가 통계적으로 유의미함 : 귀무가설 기각
➡️ p-value가 0.0089로 유의수준 0.05보다 작으므로, 세그먼트 간 재방문율 차이는 통계적으로 유의미함을 확인
3.1.2 주문 전환율 검증
- 분석 방법:
각 고객 세그먼트의 주문 전환율(장바구니 단계에서 결제 시도로 전환된 비율)에 대해 Kruskal-Wallis 검정 수행 - 검정 결과:
- 검정 통계량: 16.1657
- p-value: 0.0010
세그먼트 간 주문 전환율 차이가 통계적으로 유의미함 : 귀무가설 기각
➡️ p-value가 0.0010으로 유의수준 0.05보다 매우 낮으므로, 세그먼트 간 주문 전환율 차이도 통계적으로 유의미함을 확인
3.2 상관관계 분석
3.2.1 재방문율과 주문 횟수 간 상관분석
- 목적 : 재방문율과 주문율 간의 관련성 확인
- 분석 방법 :각 세그먼트의 평균 재방문율을 사용하여 Pearson 및 Spearman 상관분석 수행
분석 결과
| 분석 항목 | 분석 기법 | 상관계수 | p-value | 해석 |
| 재방문율 vs 주문 횟수 | Pearson | 0.9953 | 0.0047 | 매우 강한 양의 상관관계로 통계적으로 유의함 |
| 재방문율 vs 주문 횟수 | Spearman | 1.0000 | 0.0000 | 완벽한 순위 기반 양의 상관관계로 통계적으로 유의함 |
➡️ 고객의 재방문율과 주문율 간에 매우 강한 양의 상관관계가 존재하며, 통계적 유의성을 확보함
3.2.2 결론
재방문율과 주문 횟수 간 관계
- 고객이 주문을 많이 할수록 재방문율도 거의 완벽하게 증가하는 경향을 보임
- Pearson 분석에서는 상관계수가 0.9953, p-value는 0.0047로 나타났으며
- Spearman 분석에서도 완벽한 순위 기반 상관관계(상관계수 1.0000, p-value 0.0000)가 확인됨
3.4 최종 결론
가설 ❷ ("재방문 횟수가 많을수록 주문율이 높아질 것이다") : 가설 채택
- 재방문율과 주문 전환율은 세그먼트 간에 유의미한 차이가 있으며, 두 변수 간에 매우 강한 양의 상관관계가 존재함
- 따라서 "재방문율이 높을수록 주문율이 높아질 것이다" 라는 가설은 통계적으로 유의미한 근거를 통해 채택 가능
➡️ 가설 검증에 대한 결과를 기반으로 고객의 재방문을 유도하여 주문율을 개선하는 전략 필요함
4. 가설 채택
가설 채택 결과
| 가설 | 가설 내용 | 검증 결과 |
| 가설 ❶ | 담고 싶은 메뉴가 없어서 이탈했을 가능성이 크다. | 기각 |
| 가설 ❷ | 재방문 횟수가 많을수록 주문율이 높아질 것이다. | 채택 ✔️ |
- 가설 ❶은 장바구니 전환율과 일치율에서 세그먼트 간 차이가 통계적으로 유의미했으나, 주문 횟수와 일치율 간 상관분석에서 통계적 유의성을 확보하지 못하여 가설을 채택하지 않음
- 가설 ❷는 재방문율과 주문율 간 강력한 양의 상관관계가 통계적으로 유의미하게 나타나, 재방문이 많아질수록 주문으로 이어질 확률이 증가하는 것으로 나타나 채택
5. 문제 정의 : 초기 고객은 왜 재방문하지 않을까?
5.1 분석 결과 요약
가설 검증 결과, 재방문 횟수가 증가할수록 주문율이 크게 높아진다는 점이 데이터로 확인되었다.
그러나 초기 방문 고객은 재방문을 잘 하지 않으며, 이는 곧 낮은 주문율로 이어지고 있다.
채택된 가설에 기반하여, "재방문율이 높을수록 주문율이 높다"는 결과는
역으로 보면 초기 고객이 재방문을 하지 않는 이유가 주문을 방해하는 근본적 불편함일 가능성이 크다로 해석할 수 있다.
5.2 재방문을 하지 않는 근본적인 원인은?
초기 고객이 재방문하지 않는 주요 원인을 파악하면 다음과 같이 생각해볼 수 있다.
첫 방문 시 서비스 만족도의 부족
- 메뉴 탐색 과정이 복잡하거나 어려움
- 메뉴 자체가 고객의 기대에 미치지 못하거나 매력적이지 않음
- 메뉴 및 식당 정보의 신뢰도 부족
재방문을 유도하는 마케팅 및 홍보 장치 부족 ✔️
- 앱에 재방문을 유도할 매력적인 광고 및 홍보 부족
- 고객이 앱을 자주 열도록 유도하는 앱 푸시 알림이나 정기적인 출석체크, 이벤트 등 재방문 동기를 자극하는 장치 부족
즉, 고객은 첫 방문에서의 긍정적인 경험 부족뿐만 아니라, 앱을 다시 찾을 만한 매력적인 마케팅 장치의 부재로 인해 재방문하지 않고 이탈하고 있다고 해석할 수 있다.
5.3 최종 문제 정의
“초기 방문 고객은 첫 경험에서 메뉴 탐색과 선택 과정에서의 불편함과 신뢰 부족, 그리고 재방문을 유도할 수 있는 앱 내 홍보 및 마케팅 전략의 부족으로 인해 재방문하지 않는다.”
결과적으로 초기 방문 고객의 재방문을 이끌어낼 수 있는 전반적인 서비스 개선과 함께,
초기 방문 고객의 재방문 유도, 방문 동기 자극을 위한 적극적인 프로모션 및 홍보 장치가 필요하다.
'글또 > project' 카테고리의 다른 글
| 월간데이터노트 4월 : 2025 데이터 분석가 채용 공고 트렌드 분석 (1) | 2025.04.26 |
|---|---|
| 월간 데이터 노트 3월 : 성공적인 하루를 위한 나만의 조건 방정식 (0) | 2025.03.29 |
| 월간 데이터 노트 2월 : 케이크 가심비 프로젝트 (7) | 2025.03.01 |
| 사이드 프로젝트 : 배달 데이터 분석(2) - 현황 파악, 문제 정의를 위한 가설 설정 (0) | 2025.02.16 |
| 시간을 지배하는 법 : 데이터 기반 생활 패턴 개선 프로젝트 (1) | 2025.02.01 |



