똑같은 코드인데 점점 성능이 좋아지는 이유
→ 경험을 학습했기 때문, 사람과 마찬가지로 똑같은 작업을 통해서 학습을 했기 때문
Tom Mitchell 의 정의 :
- E : experience 경험을 통해
- T : task 특정 과제, 작업의
- P : performance 퍼포먼스를 개선
기계학습은 어떤 목표로 작업을 진행, 수행 경험을 학습해서 성능이 개선되는 컴퓨터 프로그래밍이다.
기계학습을 할 때 가장 많이 사용되고 표준적으로 표현되는 말로,
어떤 작업과 알고리즘이 있는데 경험에 의해 성능이 향상된다면 기계학습이다.
EX 1) 알파고의 인공지능 playing Baduk
E : experience 알파고에게 있어 경험이란? 바둑기사들이 둔 기록
T : 바둑을 이기는 것 (바둑을 두는 것이 아님)
P : 승률
EX 2) 자동 필기체인식
E : 데이터를 계속 넣어주며 경험, 학습
T : 필기체를 인식하는 것 - 7로 쓰인것을 7로 인식
P : 인식률 - 7과 9를 제대로 구분
데이터가 많을수록 학습률이 좋아지는 것은 변함없는 사실이며 데이터의 퀄리티가 보장되는 것이다.
오류데이터, outlier, 등 잘못된 데이터를 집어넣는 것이 아니라면 데이터는 많을수록 항상 성능이 좋다.
나중에 딥러닝, 머신러닝등 성능을 높이기 위한 가장 기본적인 방법은 데이터를 더 추가하는 것이다.
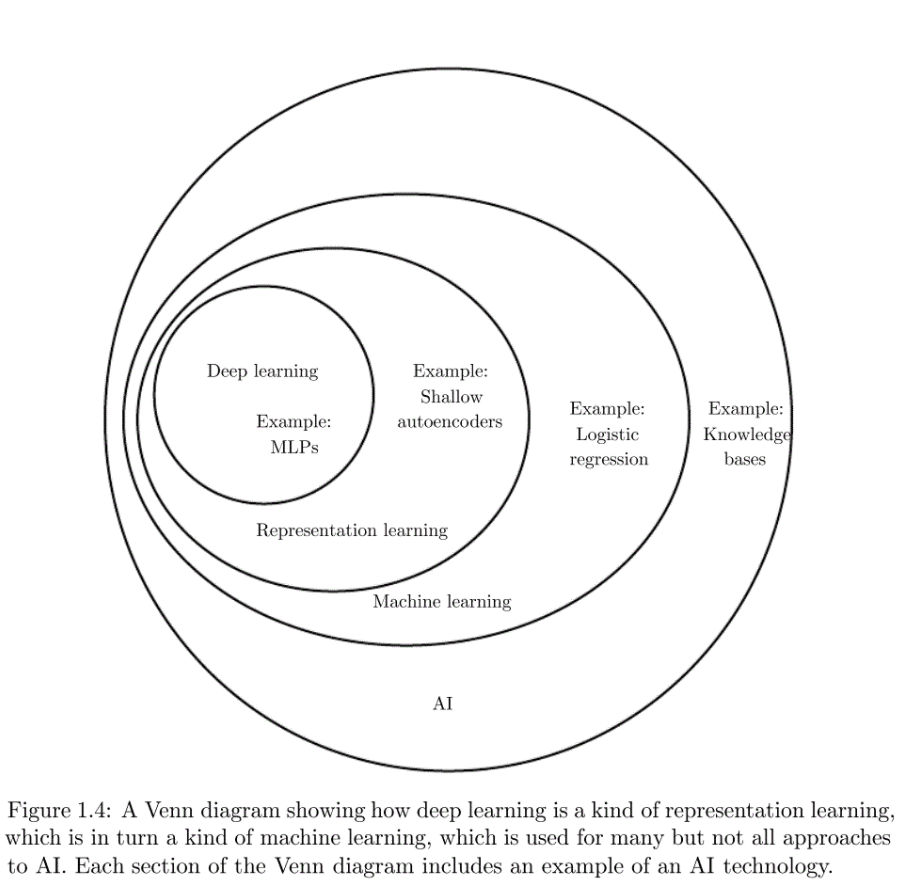
인공지능 (큰 개념) > 기계 학습 > 딥러닝 구조
하지만, 이미지와 같은 경우 설명하기가 어려움
하늘 , 색상 의 정의?
→ 이런 한계에 도달했을 때, 기계 학습의 개념이 생겨나게됨
기계학습은 뿌리가 다르다. 데이터를 중심으로
"사람이 경험을 통해 지혜로워지듯, 기계 또한 데이터를 주어서 지혜롭게 만들자"
지식기반 방식은 한계가 있음
→ 데이터로부터 학습을 해서 문제를 해결하는 기계학습이 점점 해결책이 되어가고 있음
학습하고 있는 최신 알고리즘이 나타나고 이미지 인식 분야는 (CNN)
이미지를 설명해서 규칙으로 학습시키는 것보다,
→ 차라리 비슷한 이미지의 데이터를 입력해서 학습시키는 것이 훨씬 인식력이 좋은 모델을 만들 수 있음을 알게 됨
- 이미지 데이터
- 알고리즘의 성능이 향상됨
- 점차 데이터들이 많아지고 쌓이면서 이전에 해결하지 못했던 문제들을 해결할 수 있게 되었음
⇒ 인공지능의 주도권이 지식기반에서 기계학습으로 전환되었음!
기계학습으로 할 수 있는 것
분류, 비지도학습으로 그룹, 생성, 차원축소등..
실무에서 가장 많이 필요로 하고 인공지능으로 적용되고 있는 분야는 "예측"
주식거래 예측, 환자 예측, 가능성 예측
- 기계가 학습을 하기 위해서는 데이터가 있어야함
- 데이터로부터 학습을 해서 어떤 패턴이 있는지를 찾아냄
- 학습된 데이터를 가지고 직선의 방정식을 찾아냄
- 수식을 가지고 다음 수를 예측할 수 있게됨
- 기계는 어떻게 수식을 찾아내는가?
→ Training Data : 학습을 할 데이터
기계는 랜덤으로 선택된 값과 실제 값을 비교하여 차이를 계산한다.
=⭐ 목적함수 ⭐생성
기계가 랜덤으로 값을 바꿔서 훈련하는데, 그 값을 바꾸는 전략이 필요하고 어느방향으로 값을 변경하는 것이 좋을까?
딥러닝이든 모든 기계함수는 목적함수라는 것을 갖고 있는데, 목적함수의 값이 작아지도록 값을 변경해주어야 함
"미분" : 작은 변화가 있을 때의 변화량
미분을 해서 목적함수가 작아지는 방향을 찾은 다음, 그 방향으로 값을 변형함
이 것을 언제까지 지속하는가 ?
→ 목적함수의 값이 0이 되었을 때.
목적함수의 값이 최소가 될 수 있도록 최대한 잘 맞출 수 있는 직선을 찾는다.
기계학습은 가장 잘 예측할 수 있는 최적의 매개변수를 찾는 작업이다. (최적의 직선 방정식을 찾는 것임)
기계 학습의 궁극적인 목표
중요 : 트레이닝 데이터를 통해 모델을 생성하고 트레이닝 데이터에 사용되지 않은 테스트 데이터 집합에 대해서 높은 성능을 보여야한다.
트레이닝 데이터와 테스트 데이터
- training data : 학습용
- test data : 시험용
트레이닝 데이터의 성능보다는 테스트 데이터의 성능이 더 좋아야하며 중요.
일반화 : 어떠한 데이터가 들어가도 잘 예측할 수 있어야 함
다양한 데이터를 적용해보아야함
학습한 데이터만 잘 맞추면 중요하지 않음
overfitting : 과적합 = 트레이닝 데이터만 잘 맞추는 것
특징 공간에 대한 이해
EX ) 위암환자의 데이터
환자들의 특성 : 나이 성별 흡연 음주습관 기저질환 당뇨 고혈압 등 → 변수 → 기계학습에서는 특징: feature 라고 한다 (같은 말이지만 다른 용어로 사용함)
x 축 - feature
값이 두개인 경우 : (몸무게와 키)→ feature 로 값을 예측함
예측해야 하는 값 y → 목적 함수
feature가 많을 수록 무조건 좋은 것은 아님.
내가 예측을 하는데 전혀 상관이 없는 feature가 있다면 예측하는 데 방해가 될 수 있음
선별해서 의미있는 feature를 찾아내는 것이 좋음
가지고 있는 feature가 3개 → 3차원 공간
- 비정형데이터
MNIST (이미지) data set ⇒ 16*16 = 화소 수 784차원
Farm ads (광고에 쓰인 단어의 개수) = 54877차원
텍스트 데이터의 경우 단어 하나하나가 다 feature가 됨
feature가 많아지면 의미있는 feature를 선별하기가 어려워짐 → 딥러닝을 이용
다른 알고리즘과의 특징이 딥러닝은 너무 feature가 많아서 선별이 안될때
스스로 학습해서 불필요한 feature는 값을 0으로 줄이고 필요한 것은 값을 올려주는 역할 을 함 매개변수를 스스로 학습함
도메인 전문가가 하던 일을 딥러닝에게 맡기면 데이터를 읽어서 예측하는데 필요한 변수를 스스로 선별함
딥러닝을 흔히 블랙박스 모델이라고 한다
- 장점 : 도메인 지식을 잘 몰라도 기계가 예측하는데 필요한 모델을 뽑아낸다
- 단점 : 결과가 나왔고 예측도 잘 나오지만, 설명이 어려움 왜 이러한 결과 가 나왔는지 알 수 가 없음 '
- 요즘 최신 기술인 예측 모델을 설명 가능을 추가된 기술이 들어가고 있음
→ 위암 가능성을 설명해주는 인공지능 기술
기계는 데이터의 feature를 학습하면서 잘 예측할 수 있도록 공간 변환을 한다
직선식을 변환 : 딥러닝의 경우 히든레이어가 그 역할 을 한다.
- 우리가 해야할 것
- 기계학습의 개념을 이해 : 기계학습이 일반 컴퓨터 프로그램과 무엇이 다른가 ?
- feature : 원래 변수가 의미하는 것에 대한 이해
'Note > Machine learning' 카테고리의 다른 글
| 의사 결정 트리 (0) | 2021.08.08 |
|---|---|
| 데이터 변환 (0) | 2021.08.08 |
| 데이터 정제 (0) | 2021.08.01 |
| 모델 선택 (0) | 2021.08.01 |
| 기계학습 개요(2) (2) | 2021.07.18 |


