데이터의 imbalance가 심하고 데이터가 작은 경우,
오히려 딥러닝보다 여러 개의 decision tree를 만들어놓고 합해서 다시 학습시키는 앙상블 학습 모델인
random forest나 xgb 같은 계열이 성능을 더 잘 나타낼 수 있음
의사결정트리는 결과를 시각화해서 보여주는데,
의사결정트리로 데이터가 분류되는 과정을 시각화해서 보면,
어떤 특성을 제일 먼저 선택해서 분류했는지 확인할 수 있다.
이때, 데이터 특성이나 양이 많다면 계산량도 증가하므로 시간이 오래걸리는 단점이 생기며, 이러한 단점을 보완한 랜덤포레스트 방식이 있다
⇒ 의사결정 트리를 여러 개 생성한 뒤, 학습시키는 앙상블 학습법
각 트리의 결과들을 학습시키는 방법에 따라서 종류가 나뉜다.
분류 예제
매장 손님의 국적 분류 예측을 한다면
데이터 조사
- 건물 입구에서부터 직원이 있는 곳까지 걸어 들어오는 시간
- 걸어 들어오면서 주변의 상품을 둘러보는 횟수
- 성별
특성을 학습한 뒤 목적변수를 예측한다.

매장 데이터의 의사 결정 트리
walk < 34 인경우 → 중국인
walk <36 이면서 view ≥ 10 → 중국인
walk <36 이면서 view < 10 → 일본인
함수를 호출하고 결과를 나타내는 것보다 중요한 것은,
- 결과가 나왔을 때, 믿을만한 것인지 파악
- 여러 모델의 결과물 중에 어떤 모델을 선택할 것인지
- 모델이 overfitting이 일어났을 때, 규제해서 모델의 성능을 향상시키는 작업
의사결정트리가 어떻게 생성되는지 이해해야만 조정이 가능함
의사결정트리의 핵심은 판별기준
왜 walk < 34를 첫번째 분류기준으로 삼았을까?
중국인과 일본인을 한번에 분류가 가능한 조건 → 제일 좋은 기준
동작원리
- 판별에 사용하는 변수선택이 중요
- 데이터의 순도가 가장 높아지도록 그룹을 나누는 작업
*데이터의 순도? → 중국인 or 일본인 만 모여있는 상태
- 순도가 100% 일때 가장 좋은 변수
- 가장 이상적인 의사결정트리는 순도 100% 로 나뉘는 모델이다.
그렇다면 의사결정트리는 순도100%가 되는 기준을 어떻게 찾았을까?
의사결정트리는 정보량이라는 개념을 가지고 계산한다
정보량
- 어떤 데이터가 포함하고 있는 정보의 총 기대치, 정보의 가치
- 해당 사건이 발생할 확률의 역수에 비례한다
- ex) 내일 해가 동쪽에서 뜰 확률 : 100% → 정보량이 없음, 정보가 주는 가치가 없음
- 모든사람에게 알려지지 않은 희귀한 정보 , 발생하기 어려운 사건의 확률 → 정보량이 큼, 정보의 가치가 높음
- 정보량 = log(1/p) (확률의 값이 커질 수 있기 때문에 로그를 취함)
정보량과 엔트로피
- 정보량과 발생확률의 곱 = 엔트로피 = 정보량의 기대치
- 엔트로피(entropy)는 데이터의 순도와 관련됨
- 물리에서 굉장히 혼잡한 상태 = 엔트로피가 높은 상태, 안정적인 상태 = 엔트로피가 낮은 상태로 표현
기계가 학습하면서 찾아가는 방향은 엔트로피가 높은 상황일까 낮은 상황일까?
변수가 마구 섞여있는 상황이 아닌, 순도 100%의 정확히 분류되어 있는 상황을 찾아야 하므로
→ 엔트로피가 낮은 상황이어야 한다.
사건이 동시발생 → 사건의 곱으로 나타내는데, 로그에서는 log(사건 A + B)으로 표현되며 역수는 마이너스 - 로 표현함
엔트로피를 구하는 공식
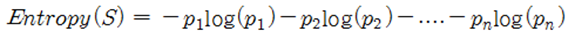
p1은 사건 A, p2는 사건 B로 사건이 동시에 발생하는 상황을 나타낸 것
결국, 의사결정트리에서는 엔트로피 값이 작은 방향으로 조건을 분리한다
의사결정 트리에 적용
- 어떤 변수를 기준을 나누었을 때 나누어진 각 하위 그룹이 얼마나 동질성 있게 = 데이터의 순도가 높아지도록 = 엔트로피의 값이 낮아지도록 잘 나누어지는지가 관건
- 동질성이 낮으면 = 데이터의 순도가 낮아지고 = 엔트로피의 값은 높아진다
- 의사결정트리의 알고리즘
데이터 선택 → 변수를 통해 기준을 다양하게 나눈다 → 엔트로피의 값이 낮은 것을 우선적으로 기준을 선택 → 모든 데이터가 순도100%가 될때까지 반복 분류함
가장 우수한 구분 변수 찾기
구분 변수 → 변수를 분류하는 기준
- 의사결정 단계마다 그룹을 가장 잘 나누는 변수 찾기
- 순도의 변화를 나타내기 위해 그룹을 나누기 전후의 엔트로피 변화량을 계산하여 측정 → 정보 이득 IG (Information Gain)
의사 결정 트리의 규제
의사결정트리에서도 과적합이 발생할 수 있는데,
훈련데이터를 맞추기위해 모든 데이터의 순도를 100%로 분류했을 경우, 트리가 너무 커짐 → 결코 좋은 모델이 될 수 없음
의사결정 트리에서는 과도한 분류를 피하기 위해 가지치기 (Pruning)을 수행한다.
- pre-pruning : 미리 정한 조건을 만족하면 분류를 멈춤 (트리의 깊이를 지정, 순도지정) → 가장 많이 사용
- post-pruning : 일단 자세하게 트리를 만든 후, 트리의 구조를 줄임
의사결정트리는 데이터의 불균형 영향을 덜받는 알고리즘으로 알려져있으나,
데이터의 크기나 feature가 너무 많을 경우 해석이 힘들어지며 계산량이 많아짐.
랜덤 포레스트 (Random Forest)
- 의사 결정 트리의 성능을 개선한 방법
- 여러 모델의 평균치를 구하는 앙상블 학습 모델
- 주어진 훈련 데이터의 일부만 사용하여 여러 개의 모델을 만들어보고 그 중 가장 좋은 모델을 선택하는 방식
- 영향력이 큰 특징 변수만 찾아 사용하므로, 특징 변수가 많은 경우 사용하기 적합
- 모델의 동작을 직관적으로 설명하기 어려우며 (의사결정트리보다는) 계산량이 많아진다는 단점
데이터가 정형데이터이며 , feature나 데이터의 양이 크지 않다면 의사결정트리 모델만을 사용해도 되지만
성능이 좋지 않고 데이터의 특징이나 사이즈가 크다면 랜덤포레스트를 이용하는 것이 좋다.
'Note > Machine learning' 카테고리의 다른 글
| 데이터 변환 (0) | 2021.08.08 |
|---|---|
| 데이터 정제 (0) | 2021.08.01 |
| 모델 선택 (0) | 2021.08.01 |
| 기계학습 개요(2) (2) | 2021.07.18 |
| 기계학습 개요 (1) | 2021.07.18 |


